The activation function: 1D classifier
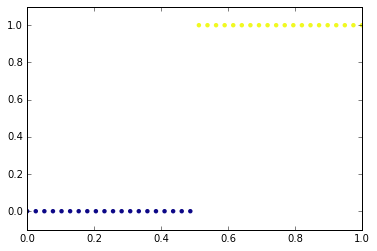 Classification is about tagging data: associate to each input a class. Let's take the following very simple problem: we have 40 values between 0 and 1. Each of them is tagged with 0 or 1: 0 if X is less than 0.5 and 1 otherwise.
Classification is about tagging data: associate to each input a class. Let's take the following very simple problem: we have 40 values between 0 and 1. Each of them is tagged with 0 or 1: 0 if X is less than 0.5 and 1 otherwise.size = 40
X_train = np.linspace(0,1,size) y_train = (X_train > 0.5)
We want to predict the tag given the value
 Let's use one single neuron, which does the following calculation:
Let's use one single neuron, which does the following calculation:$WX+b$.
We now use an activation function, a function that further transforms the previous calculation. We use sigmoid, which is defined as $\sigma(t) = \frac 1 {1+e^{-x}}$.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
We now calculate our predicted Y as $\sigma(WX+b)$. W will change the slope and b (in fact -b/W) shift the curve horizontally.
 So the idea will be to find the right parameters for W and b so the S shape function is the "closest" to the training parameters. This is done by defining a distance function and minimizing the loss, which is the sum of distances.
So the idea will be to find the right parameters for W and b so the S shape function is the "closest" to the training parameters. This is done by defining a distance function and minimizing the loss, which is the sum of distances.We see in the figure on the right a poorly fitted S shape, with W=15 and b = -0.3*W. Clearly we can do better.
The best W and b are found as the parameters that minimize the error. That can be done very simply with Keras as follows:
model = Sequential()
model.add(Dense(1, input_dim=1))
model.add(Activation("sigmoid"))
model.compile(loss=losses.binary_crossentropy, optimizer='sgd')
model.fit(X_train, y_train, nb_epoch=1000, verbose=False)
The result is a well centered sigmoid function that properly predicts the tag.

This is actually equivalent to do a logistic regression.
No comments:
Post a Comment